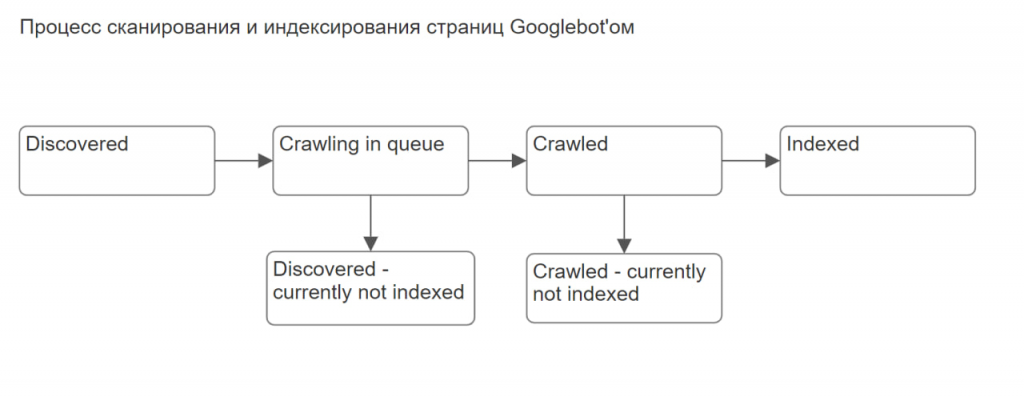
Процесс на схеме выглядит так. Это в случае пригодных для индексирования страниц, т.е. за исключением 404, редиректов, неканонических и пр.
Предполагаю, что:
— оптимизация crawl budget, общее качество и авторитетность сайта, техническая доступность и скорость в первую очередь влияют на кол-во урлов со статусом Discovered — currently not indexed
— работа над качеством конкретных страниц (и групп/паттернов урлов) влияет на кол-во урлов со статусом Crawled — currently not indexed.